Welcome to my Blog!
这里记录着我的学习之路-
隐马尔可夫链
前言
隐马尔可夫模型(Hidden Markov Model,简称HMM),是可以用来标注问题的统计学习模型,描述由马尔可夫链随机生成观测序列的过程,属于生成式模型。 在正常的马尔可夫模型中,状态对于观测者来说是直接可见的。这样状态的转换概率便是全部的参数。而在隐马尔可夫模型中,状态并不是直接可见的,但是受状态影响的某些变量是可见的。每一个状态在可能输出的符号上都有一个概率分布,因此输出序列能否透露出状态序列的一些信息。
HMM模型的定义
隐马尔可夫模型由初始概率分布,状态转移概率分布以及观测概率分布确定。 我们假设Q是所有可能的隐藏状态的集合,V是所有可能的观测状态的集合,即:
其中,N是可能的状态数,M是可能的观测数。 I是长度为T的状态序列,O是对应的观测序列。
A是状态转移概率矩阵:
其中,
表示在时刻t处于状态$q_i$的条件下在时刻t+1转移到状态$q_j$的概率。
B是观测概率矩阵:
其中,
表示在时刻t处于状态$q_j$的条件下生成观测$v_k$的概率。
$\pi$是初始状态概率向量:
其中:
表示时刻t=1处于状态$q_i$的概率。
一个马尔可夫模型,可以有隐藏状态的初始概率分布$\pi$,状态转移矩阵A和观测状态转移矩阵B决定,$\pi$,A决定状态序列,B决定观测序列。因此,隐马尔可夫模型$\lambda$可以用三员符号表示,即:
$\pi$,A,B称为隐马尔可夫模型的三要素。
隐马尔可夫做了两个很重要的基本能假设:
1、齐次马尔可夫假设,即假设隐藏的马尔可夫链在任意时刻t的状态只依赖于前一时刻的状态,于其他时刻的状态及观察无关,也与时刻t无关,即:
2、观察独立性假设,即假设任意时刻的观测值依赖于该时刻的马尔可夫链的状态,与其他观测及状态无关,即:
HMM的3个经典问题
HMM模型建立起来后,一般我们会讨论3个问题:
1、评估问题:给定模型$\lambda=(A,B,\pi)$和观测序列$O=(o_1,o_2,…,o_T)$,计算在模型$\lambda$下观测序列O出现的概率 => (前向算法)
2、预测问题:也称解码,给定观测序列O和模型参数$\lambda$,我们怎样选择一个状态序列,以便能够最好的解释观测序列,即求最有可能的状态序列(条件概率 最大)。=> (维比特算法)
3、学习问题:给定观测序列O,找到一个能最好的解释观测序列的模型$\lambda=(A,B,\pi)$,即使得 最大。=> (EM算法,前后向算法)
评估描述
给定观测序列$O=(o_1,o_2,…,o_T)$和模型$\lambda=(A,B,\lambda)$,求观测序列O出现的概率最大的概率$P(O|\lambda)$。解决该问题的最直观的想法是把所有可能的隐藏状态都遍历一遍,得到对应观测状态的概率有多大,这些可能全部加起来就是得到这个观测状态的可能性。 1、全概率公式求解观测序列在所有可能的隐藏状态序列下的概率之和。
2、任意隐藏状态序列$I=(i_1,i_2,…,i_T)$的概率是
3、已知状态序列$\lambda$下,观测序列$O=(o_1,o_2,…,o_T)$的概率
4、O和I同时出现的联合概率为:
5、对所有可能的隐藏状态序列I求和得:
利用上式计算量很大,达到$O(TN^T)$阶,在状态集合和隐藏状态序列比较短时,还是有可能穷举所有可能的状态序列,如果长的话,穷举的数量太大,指数级的,就很难完成。
前向算法
给定HMM模型$\lambda$,定义到时刻t部分观测序列为$o_1,o_2,..o_t$且状态为$q_i$的概率为前向概率,记为:
通过递推求得前向概率$\alpha_t(i)$即观测序列概率
算法
输入:隐马尔可夫模型$\lambda$,观测序列O 输出:观测序列概率$P(O|\lambda)$ 1、初值
2、递推,对t=1,2,…,T-1
3、终止
预测描述
近似算法
维比特算法
维比特算法实际是用动态规划解马尔可夫模型的预测问题,即用动态规划求概率最大路径,这时一条路径对应着一个状态序列。
算法
输入:模型$\lambda=(A,B,\pi)$和观测序列
输出:最优路径
1、初始化:
2、递推,对
3、终止
4、最优路径回溯,对$t=T-1,T-2,…,1$
求得
-
EM算法
凸函数
开始EM算法前,我们先讨论凸函数。连续函数的一阶导数就是相应的切线斜率。一阶导数大于0,则递增;一阶倒数小于0,则递减;一阶导数等于0,则不增不减。 而二阶导数可以反映图象的凹凸。二阶导数大于0,图象为凹;二阶导数小于0,图象为凸;二阶导数等于0,不凹不凸。
现设一函数f(x),在该函数定义域的凸区间内任取两点$x_1$,$x_2$, 其中$x_1<x_2$,设一点$x=q_1x_1+q_2x_2$,($q_1$,$q_2>0$且$q_1+q_2=1$),那么该点必包含于$x_1$,$x_2$之间。
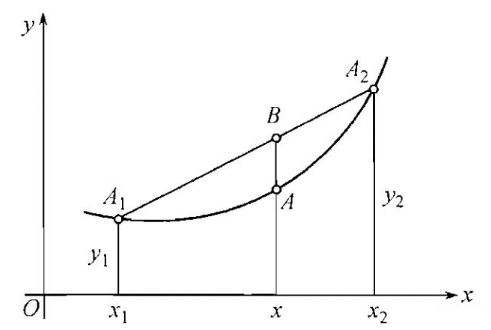
图中包含点$A_1(x_1,x_2)$、$A_2(x_2,x_2)$,$A(x,f(x))$,先构建线性函数两点式,代入$A_1(x_1,x_2)$、$A_2(x_2,x_2)$两点,再代入B点的横坐标,得到其纵坐标:
同时利用$x=q_1x_1+q_2x_2$可以得:
所以B的纵坐标是:
结合上图,显然:
且当$x_1 -> x_2$时,可以等号成立。
总结下:
在区间X上,有定义而且连续的函数$f(x)$叫做凸函数(往下凸),如果对于区间x中的任何两点$x_1$和$x_2(x_2>=x_1)$有不等式:同理,当函数为凹函数是:
Jensen不等式
刚刚我们已经证明的凸函数的代数定义:
将其一般化,便容易推出:
将形式更加简化得:
在概率论中,如果把$p_i$看成是取值为$x_i$的离散变量x的概率分布,那么上式可以写成:
其中$E(.)$表示期望。
EM算法
EM算法是一种迭代算法,主要用来处理含有隐变量(hidden variable)的概率参数的极大似然估计,或者极大后验概率估计。EM算法的每次迭代分为两步:E步,求期望;M步,求极大。所以该算法称为期望极大算法(expectation maximization algorithm),简称EM算法。
EM算法公式推导
推导过程参照李航<统计学习方法>,加上个人理解。
当我们面对一个含有隐变量的概率模型时,我们的最终目标是要极大化观测数据$Y$关于参数$\theta$的对数似然函数,即极大化:
将所有隐变量于观测数据$Y$的所有联合概率相加,即:
注意到要极大化上式非常困难的,式中不仅有未观测数据$Z$,还包含了求和的对数,对未知变量求导后等于0的式子仍然十分复杂。 我们可以通过迭代的方式不断的逼近极大化的$L(\theta)$,假设在第i次的迭代后的$\theta$的估计值是$theta^{(i)}$,如果能够使新估计的$\theta$,让$L(\theta)$增加,即,使得$L(\theta)>L(\theta^{(i)})$,那么在一次次的迭代之后,最终会逼近$L(\theta)$的极大值。 即:
利用上面的Jensen不等式,得到其下界:
因为$P(Z|Y,\theta^{(i)})$是Z关于Y的概率分布,所以: 即上式:
令:
则:$L(\theta)≥B(\theta,\theta^{(i)})$,即函数$B(\theta,\theta^{(i)})$是$L(\theta)$的一个下界,由上面的式子可知:
因此对于任何能使$B(\theta,\theta^{(i)})$增大的$\theta$,也同时可以使$L(\theta)$增大,为了使$L(\theta)$增大,选择$\theta^{(i)}$使得$B(\theta,\theta^{(i)})$达到极大,即:
去掉不相关的常数:
EM算法的收敛性证明
由于:
两边取对数有:
等式两边同时对分布 求期望得:
等式左边与Z无关,分布求和等于1,于是:
分别取$\theta$为$\theta^{(i)}$和$\theta^{(i+1)}$并相减,有:
要使收敛性成立,只需上式右端是非负即可,又由于$Q(\theta^{(i+1)})$是$Q(\theta,\theta^{(i)})$达到极大,所以有$Q(\theta^{(i+1)},\theta^{(i)})-Q(\theta^{(i)},\theta^{(i)})≥0$, 要使右端为非负,只需$H(\theta^{(i+1)},\theta^{(i)})-H(\theta^{(i)},\theta^{(i)})≤0$,于是:
即收敛性得证。